Mass is a simple concept, which is better understood by comparison. For instance, a long function has bigger mass than a short one. A class with several methods and fields has bigger mass than a class with just a few methods and fields. A database with a large number of tables has bigger mass than a database with a few. A database table with many fields has bigger mass than a table with just a few. And so on.
Mass, as discussed above, is a static concept. We don't look at the number of records in a database, or at the number of instances for a class. Those numbers are not irrelevant, of course, but they do not contribute to mass as discussed here.
Although we can probably come up with a precise definition of mass, I'll not try to. I'm fine with informal concepts, at least at this time.
Mass exerts gravitational attraction, which is probably the most primitive force we (as software designers) have to deal with. Gravitational attraction makes large functions or classes to attract more LOCs, large components to attract more classes and functions, monolithic programs to keep growing as monoliths, 1-tier or 2-tiers application to fight as we try to add one more tier. Along the same lines, a single large database will get more tables; a table with many fields will attract more fields, and so on.
We achieve low mass, and therefore smaller and balanced gravity, through careful partitioning. Partitioning is an essential step in software design, yet separation always entails a cost. It should not surprise you that the cost of [fighting] gravity has the same fractal nature of separation.
A first source of cost is performance loss:
- Hardware separation requires serialization/marshaling, network transfer, synchronization, and so on.
- Process separation requires serialization/marshaling, synchronization, context switching, and so on.
- In-process component separation requires indirect function calls or load-time fix-up, and may require some degree of marshaling (depending on the component technology you choose)
- Interface – Implementation separation requires (among other things) data to be hidden (hence more function calls), prevents function inlining (or makes it more difficult), and so on.
- In-component access protection prevents, in many cases, exploitation of the global application state. This is a complex concept that I need to defer to another time.
- Function separation requires passing parameters, jumping to a different instruction, jumping back.
- Mass storage separation prevents relational algebra and query optimization.
- Different tables require a join, which can be quite costly (here the number of records resurfaces!).
- (the overhead of in-memory separation is basically subsumed by function separation).
A second source of cost is scaffolding and plumbing:
- Hardware separation requires network services, more robust error handling, protocol design and implementation, bandwidth estimation and control, more sophisticated debugging tools, and so on.
- Process separation requires most of the same.
- And so on (useful exercise!)
A third source of cost is human understanding:
Unfortunately, many people don’t have the ability to reason at different abstraction levels, yet this is exactly what we need to work effectively with a distributed, component-based, multi-database, fine-grained architecture with polymorphic behavior. The average programmer will find a monolithic architecture built around a single (albeit large) database, with a few large classes, much easier to deal with. This is only partially related to education, experience, and tools.
The ugly side of gravity is that it’s a natural, incremental, attractive, self-sustaining force.
It starts with a single line of code. The next line is attracted to the same function, and so on. It takes some work to create yet another function; yet another class; yet another component (here technology can help or hurt a lot); yet another process.
Without conscious appreciation of other forces, gravity makes sure that the minimum resistance path is followed, and that’s always to keep things together. This is why so much software is just a big ball of mud.
Enough for today. Still, there is more to say about mass, gravity and inertia, and a lot more about other (balancing) forces, so see you guys soon...
Breadcrumb trail: instance/record count cannot be ignored at design time. Remember to discuss the underlying forces.
Saturday, December 06, 2008
Sunday, November 30, 2008
Notes on Software Design, Chapter 1: Partitioning
In a previous post, I discussed Alexander’s theory of Centers from a software design perspective. My (current) theory is that a Center is (in software) a locus of highly cohesive information.
It is worth noting that in order to create highly cohesive units, we must be able to separate things. This may seem odd at first, since cohesion (as a force) is about keeping things together, not apart, but is easily explained.
Without some way to partition knowledge, we would have to keep everything together. In the end, conceptual cohesion will be low, because a multitude of concepts, abstractions, etc., would all mash up into an incoherent mess.
Let’s focus on "executable knowledge", and therefore leave some artifacts (like requirement documents) away for a while. We can easily see that we have many ways to separate executable knowledge, and that those ways apply at different granularity levels.
- Hardware separation (as in distributed computing).
- Process separation (a lightweight form of distributed computing, with co-located processes).
- In-process component separation (e.g. DLLs).
- Interface – Implementation separation (e.g. interface inheritance in OO languages).
- In-component access protection, like public/private class members, or other visibility mechanism like modules in Modula 2.
- Function separation (simply different functions).
Knowledge is not necessarily encoded in code – it can be encoded in data too. We have several ways to partition data as well, and they apply to the entire hierarchy of storage.
- Mass storage separation (that is, using different databases).
- Different tables (or equivalent concept) within the same mass storage.
- Module or class static data (inaccessible outside the module).
- Data member (inaccessible outside the instance).
- Local / stack based variables (inaccessible outside the function).
It is interesting to see how poor data separation can harm code separation. Sharing tables works against hardware separation. Shared memory works against process separation. Global data with extern visibility works against module separation. Get/Set functions work against in-component access protection.
Code and data separation are not orthogonal concepts, and therefore they can interfere with each other.
There is more to say about separation and its relationship with old concepts like coupling (straight from the '70s). More on this another time; right now, I need to set things up for Chapter 2.
In the same post above, I mentioned the idea that centers have fractal nature, that is, they appear at different abstraction and granularity levels. If there are primordial forces in software, it seems reasonable that they follow the same fractal nature: in other words, they should apply at all abstraction levels, perhaps with a different slant.
The first force we have to deal with is Gravity. Gravity works against separation, and as such, is a force we cannot ignore. Gravity, as in physics, has to do with Mass, and another manifestation of Mass is Inertia. Gravity, like in the physical world, is a pervasive force, and therefore, separation always entails a cost. Surrending to gravity, however, won't make your software fly :-). I’ll talk about all this very soon.
On a more personal note, I haven’t said much about running lately. I didn’t give up; I just have nothing big to tell :-). Anyway: there is still a little snow around here, but I was beginning to feel like a couch potato today, so I geared up and went for a 10Km (slow :-) run. At Km 4 it started raining :-)), but not so much to require an about face. At Km 8 the rain stopped, and I ran my last 2 Km slightly faster. It feels so great to be alive :-).
It is worth noting that in order to create highly cohesive units, we must be able to separate things. This may seem odd at first, since cohesion (as a force) is about keeping things together, not apart, but is easily explained.
Without some way to partition knowledge, we would have to keep everything together. In the end, conceptual cohesion will be low, because a multitude of concepts, abstractions, etc., would all mash up into an incoherent mess.
Let’s focus on "executable knowledge", and therefore leave some artifacts (like requirement documents) away for a while. We can easily see that we have many ways to separate executable knowledge, and that those ways apply at different granularity levels.
- Hardware separation (as in distributed computing).
- Process separation (a lightweight form of distributed computing, with co-located processes).
- In-process component separation (e.g. DLLs).
- Interface – Implementation separation (e.g. interface inheritance in OO languages).
- In-component access protection, like public/private class members, or other visibility mechanism like modules in Modula 2.
- Function separation (simply different functions).
Knowledge is not necessarily encoded in code – it can be encoded in data too. We have several ways to partition data as well, and they apply to the entire hierarchy of storage.
- Mass storage separation (that is, using different databases).
- Different tables (or equivalent concept) within the same mass storage.
- Module or class static data (inaccessible outside the module).
- Data member (inaccessible outside the instance).
- Local / stack based variables (inaccessible outside the function).
It is interesting to see how poor data separation can harm code separation. Sharing tables works against hardware separation. Shared memory works against process separation. Global data with extern visibility works against module separation. Get/Set functions work against in-component access protection.
Code and data separation are not orthogonal concepts, and therefore they can interfere with each other.
There is more to say about separation and its relationship with old concepts like coupling (straight from the '70s). More on this another time; right now, I need to set things up for Chapter 2.
In the same post above, I mentioned the idea that centers have fractal nature, that is, they appear at different abstraction and granularity levels. If there are primordial forces in software, it seems reasonable that they follow the same fractal nature: in other words, they should apply at all abstraction levels, perhaps with a different slant.
The first force we have to deal with is Gravity. Gravity works against separation, and as such, is a force we cannot ignore. Gravity, as in physics, has to do with Mass, and another manifestation of Mass is Inertia. Gravity, like in the physical world, is a pervasive force, and therefore, separation always entails a cost. Surrending to gravity, however, won't make your software fly :-). I’ll talk about all this very soon.
On a more personal note, I haven’t said much about running lately. I didn’t give up; I just have nothing big to tell :-). Anyway: there is still a little snow around here, but I was beginning to feel like a couch potato today, so I geared up and went for a 10Km (slow :-) run. At Km 4 it started raining :-)), but not so much to require an about face. At Km 8 the rain stopped, and I ran my last 2 Km slightly faster. It feels so great to be alive :-).
Sunday, September 21, 2008
... and Found?
What is a center in software? Although I gave the subject some serious thinking, my answer is quite simple; in fact, we knew it all along.
Let's recap Alexander's definition:
Centers are those particular identified sets, or systems, which appear within the larger whole as distinct and noticeable parts. They appear because they have noticeable distinctness, which makes them separate out from their surroundings and makes them cohere, and it is from the arrangements of these coherent parts that other coherent parts appear.
We might be tempted to define centers as the main decomposition mechanism in some paradigm. For instance, we could say that centers are classes. In fact, if you change "centers" with "classes" in the text above, it still makes sense. Of course, that would be the wrong answer. Is is functions, then? This is the path Jim took, until he got down to the spatial properties of code and so on. I'll try the road less traveled by.
I've often quoted Philip Armour saying that software development is a knowledge acquisition activity. In Listen to your Tools and Materials, I went one small step further and said "Our material is knowledge, or information.We acquire, understand, filter, and structure information".
Information is often assimilated with data, as in data structures, databases, and so on. That's a limiting view, as it could only be applied to finite sets, defined extensionally. Information can also be captured intensionally, by defining predicates. Information can be captured procedurally, by defining processes. This is where I first depart from Jim. I see no need to transform procedures into spatial data structures. Procedures are fine just as they are: information encoded through a process.
It is interesting to see that the act of acquiring and encoding information permeates all phases (or activities) of software development. We analyze requirements by understanding, classifying, encoding information. It doesn't really matter if the result is a use case, a class diagram, a piece of code, some natural text, a set of test cases. We structure information during design, while coding, even while indenting text. It may be turtles :-) all the way down in meatspace, but it's information all the way down in cyberspace.
This is exactly the kind of fractal nature we were looking for. However, the magic X is not simply information: it's highly cohesive information. OK, that was it :-).
The concept scales very well across a number of paradigms, artifacts, scales. A few examples:
- a good class is a set of cohesive methods and data
- a good module is a set of cohesive classes or functions
- a good function (or method) manipulates cohesive input through a cohesive process (separation of concerns) giving out a cohesive output (information hiding)
- a good aspect brings scattered concerns together into a single, cohesive point of development, maintenance, and reuse.
- empty lines in source code are used to separate highly cohesive portions of code.
- proper layout in UML class/component diagrams is used to aggregate highly cohesive portions.
- and so on.
So what is a center? A center is a locus of highly cohesive information. The form of a center is influenced by our paradigm and our material. But as I contended a couple of years ago in a post I prophetically :-) titled Unifying Concepts, paradigms are all about one single principle. Partitioning knowledge, I said then. Partitioning information in highly cohesive sets (or loci), I should say now.
What about Jim question? What kind of x is there that makes it true to say that every successful program is an x of x's? Highly cohesive information, of course! From subsystems to components, down to grouping and indentation of source code.
I began this post by saying we knew it all along. In a sense, we did: in another prophetic post (More synchronicity, do I need to say more? :-), I quoted Yourdon saying that he got the concept of cohesion while reading Alexander.
That kinda closes the circle, doesn't it?
Let's recap Alexander's definition:
Centers are those particular identified sets, or systems, which appear within the larger whole as distinct and noticeable parts. They appear because they have noticeable distinctness, which makes them separate out from their surroundings and makes them cohere, and it is from the arrangements of these coherent parts that other coherent parts appear.
We might be tempted to define centers as the main decomposition mechanism in some paradigm. For instance, we could say that centers are classes. In fact, if you change "centers" with "classes" in the text above, it still makes sense. Of course, that would be the wrong answer. Is is functions, then? This is the path Jim took, until he got down to the spatial properties of code and so on. I'll try the road less traveled by.
I've often quoted Philip Armour saying that software development is a knowledge acquisition activity. In Listen to your Tools and Materials, I went one small step further and said "Our material is knowledge, or information.We acquire, understand, filter, and structure information".
Information is often assimilated with data, as in data structures, databases, and so on. That's a limiting view, as it could only be applied to finite sets, defined extensionally. Information can also be captured intensionally, by defining predicates. Information can be captured procedurally, by defining processes. This is where I first depart from Jim. I see no need to transform procedures into spatial data structures. Procedures are fine just as they are: information encoded through a process.
It is interesting to see that the act of acquiring and encoding information permeates all phases (or activities) of software development. We analyze requirements by understanding, classifying, encoding information. It doesn't really matter if the result is a use case, a class diagram, a piece of code, some natural text, a set of test cases. We structure information during design, while coding, even while indenting text. It may be turtles :-) all the way down in meatspace, but it's information all the way down in cyberspace.
This is exactly the kind of fractal nature we were looking for. However, the magic X is not simply information: it's highly cohesive information. OK, that was it :-).
The concept scales very well across a number of paradigms, artifacts, scales. A few examples:
- a good class is a set of cohesive methods and data
- a good module is a set of cohesive classes or functions
- a good function (or method) manipulates cohesive input through a cohesive process (separation of concerns) giving out a cohesive output (information hiding)
- a good aspect brings scattered concerns together into a single, cohesive point of development, maintenance, and reuse.
- empty lines in source code are used to separate highly cohesive portions of code.
- proper layout in UML class/component diagrams is used to aggregate highly cohesive portions.
- and so on.
So what is a center? A center is a locus of highly cohesive information. The form of a center is influenced by our paradigm and our material. But as I contended a couple of years ago in a post I prophetically :-) titled Unifying Concepts, paradigms are all about one single principle. Partitioning knowledge, I said then. Partitioning information in highly cohesive sets (or loci), I should say now.
What about Jim question? What kind of x is there that makes it true to say that every successful program is an x of x's? Highly cohesive information, of course! From subsystems to components, down to grouping and indentation of source code.
I began this post by saying we knew it all along. In a sense, we did: in another prophetic post (More synchronicity, do I need to say more? :-), I quoted Yourdon saying that he got the concept of cohesion while reading Alexander.
That kinda closes the circle, doesn't it?
Saturday, September 13, 2008
Lost
I’ve been facing some small, tough design problems lately: relatively simple cases where finding a good solution is surprisingly hard. As usual, it’s trivial to come up with something that “works”; it’s also quite simple to come up with a reasonably good solution. It’s hard to come up with a great solution, where all forces are properly balanced and something beautiful takes shape.
I like to think visually, and since standard notations weren’t particularly helpful, I tried to represent the problem using a richer, non-standard notation, somehow resembling Christopher Alexander’s sketches. I wish I could say it made a huge difference, but it didn’t. Still, it was quite helpful in highlighting some forces in the problem domain, like an unbalanced multiplicity between three main concepts, and a precious-yet-fragile information hiding barrier. The same forces are not so visible in (e.g.) a standard UML class diagram.
Alexander, even in his early works, strongly emphasized the role of sketches while documenting a pattern. Sketches should convey the problem, the process to generate or build a solution, and the solution itself. Software patterns are usually represented using a class diagram and/or a sequence diagram, which can’t really convey all that information at once.
Of course, I’m not the first to spend some time pondering on the issue of [generative] diagrams. Most notably, in the late ‘90s Jim Coplien wrote four visionary articles dealing with sketches, the geometrical properties of code, alternative notations for object diagrams, and some (truly) imponderable questions. Those papers appeared on the long-dead C++ Report, but they are now available online:
Space-The final frontier (March 1998)
Worth a thousand words (May 1998)
To Iterate is Human, To Recurse, Divine (July/August 1998)
The Geometry of C++ Objects (October 1998)
Now, good ol’ Cope has always been one of my favorite authors. I’ve learnt a lot from him, and I’m still reading most of his works. Yet, ten years ago, when I read that stuff, I couldn’t help thinking that he lost it. He was on a very difficult quest, trying to define what software is really about, what beauty in software is really about, trying to adapt theories firmly grounded in physical space to something that is not even physical. Zen and the Art of Motorcycle Maintenance all around, some madness included :-).
I re-read those papers recently. That weird feeling is still here. Lights and shadows, nice concepts and half-baked ideas, lot of code-centric reasoning, overall confusion, not a single strong point. Yeah, I still think he lost it, somehow :-), and as far as I know, the quest ended there.
Still, his questions, some of his intuitions, and even some of his most outrageous :-) ideas were too good to go wasted.
The idea of center, that he got from The Nature of Order (Alexander’s latest work) is particularly interesting. Here is a quote from Alexander:
Centers are those particular identified sets, or systems, which appear within the larger whole as distinct and noticeable parts. They appear because they have noticeable distinctness, which makes them separate out from their surroundings and makes them cohere, and it is from the arrangements of these coherent parts that other coherent parts appear.
Can we translate this concept into the software domain? Or, as Jim said, What kind of x is there that makes it true to say that every successful program is an x of x's?. I’ll let you read what Jim had to say about it. And then (am I losing it too? :-) I’ll tell you what I think that x is.
Note: guys, I know some of you already think I lost it :-), and would rather read something about (e.g.) using variadic templates in C++ (which are quite cool, actually :-) to implement SCOOP-like concurrency in a snap. Bear with me. There is more to software design than programming languages and new technologies. Sometimes, we gotta stretch our mind a little.
Anyway, once I get past the x of x thing, I’d like to talk about one of those wicked design problems. A bit simplified, down to the essential. After all, as Alexander says in the preface of “Notes on the Synthesis of Form”: I think it’s absurd to separate the study of designing from the practice of design. Practice, practice, practice. Reminds me of another book I read recently, an unconventional translation of the Analects of Confucius. But I’ll save that for another time :-).
I like to think visually, and since standard notations weren’t particularly helpful, I tried to represent the problem using a richer, non-standard notation, somehow resembling Christopher Alexander’s sketches. I wish I could say it made a huge difference, but it didn’t. Still, it was quite helpful in highlighting some forces in the problem domain, like an unbalanced multiplicity between three main concepts, and a precious-yet-fragile information hiding barrier. The same forces are not so visible in (e.g.) a standard UML class diagram.
Alexander, even in his early works, strongly emphasized the role of sketches while documenting a pattern. Sketches should convey the problem, the process to generate or build a solution, and the solution itself. Software patterns are usually represented using a class diagram and/or a sequence diagram, which can’t really convey all that information at once.
Of course, I’m not the first to spend some time pondering on the issue of [generative] diagrams. Most notably, in the late ‘90s Jim Coplien wrote four visionary articles dealing with sketches, the geometrical properties of code, alternative notations for object diagrams, and some (truly) imponderable questions. Those papers appeared on the long-dead C++ Report, but they are now available online:
Space-The final frontier (March 1998)
Worth a thousand words (May 1998)
To Iterate is Human, To Recurse, Divine (July/August 1998)
The Geometry of C++ Objects (October 1998)
Now, good ol’ Cope has always been one of my favorite authors. I’ve learnt a lot from him, and I’m still reading most of his works. Yet, ten years ago, when I read that stuff, I couldn’t help thinking that he lost it. He was on a very difficult quest, trying to define what software is really about, what beauty in software is really about, trying to adapt theories firmly grounded in physical space to something that is not even physical. Zen and the Art of Motorcycle Maintenance all around, some madness included :-).
I re-read those papers recently. That weird feeling is still here. Lights and shadows, nice concepts and half-baked ideas, lot of code-centric reasoning, overall confusion, not a single strong point. Yeah, I still think he lost it, somehow :-), and as far as I know, the quest ended there.
Still, his questions, some of his intuitions, and even some of his most outrageous :-) ideas were too good to go wasted.
The idea of center, that he got from The Nature of Order (Alexander’s latest work) is particularly interesting. Here is a quote from Alexander:
Centers are those particular identified sets, or systems, which appear within the larger whole as distinct and noticeable parts. They appear because they have noticeable distinctness, which makes them separate out from their surroundings and makes them cohere, and it is from the arrangements of these coherent parts that other coherent parts appear.
Can we translate this concept into the software domain? Or, as Jim said, What kind of x is there that makes it true to say that every successful program is an x of x's?. I’ll let you read what Jim had to say about it. And then (am I losing it too? :-) I’ll tell you what I think that x is.
Note: guys, I know some of you already think I lost it :-), and would rather read something about (e.g.) using variadic templates in C++ (which are quite cool, actually :-) to implement SCOOP-like concurrency in a snap. Bear with me. There is more to software design than programming languages and new technologies. Sometimes, we gotta stretch our mind a little.
Anyway, once I get past the x of x thing, I’d like to talk about one of those wicked design problems. A bit simplified, down to the essential. After all, as Alexander says in the preface of “Notes on the Synthesis of Form”: I think it’s absurd to separate the study of designing from the practice of design. Practice, practice, practice. Reminds me of another book I read recently, an unconventional translation of the Analects of Confucius. But I’ll save that for another time :-).
Tuesday, May 27, 2008
On the concept of Form (3): the Force Field
Warning: :-) this post is going to be somehow conceptual. I'll soon move to some real-world, software-based example, but I really need to introduce some concepts first.
The notion of force field might be unfamiliar to some, so I'll borrow a great example from Alexander himself. Consider your first "requirement" (for a system yet to be built) as a permanent magnet of some size and shape. If you place a flat glass over that magnet, and drop some iron filings on it, the iron will naturally dispose along the magnetic field lines. That gives us an image of [a section of] the force field. Now add another magnet: the shape of the field will change, as the magnets are interacting, thereby shaping a more complex force field.
We can change the [shape of the] field in many ways: moving magnets around, changing their shape, their magnetization, or even adding some shields around magnets.
The great thing about the magnetic field is that we can somehow observe its shape. Indeed, if our goal was to create a form that can be put into effortless contact with the field, we'll just have to replicate the same form that the magnetic field is giving to the iron filings. As Alexander says (NoTSoF, page 21), "once we have a diagram of forces [...] this will in essence also describe the form as a complementary diagram of forces".
In the real world, and even more so in the software world, we are never so lucky: the force field is invisible and tends also to be highly unstable.
Usually, the force field of a software project starts with Requirements. Requirements are often categorized in some way, like "functional" and "nonfunctional", or "user requirements" and "system requirements. However, requirements of any kind are just like magnets: they contribute to shape the overall field.
Requirements are just one kind of force, that is, they are not alone in shaping the field. Many technological choices we make, sometimes very (or too) early, are also shaping the force field.
Consider a simple business application. Once you decide that you'll build a web application, you have added quite a few powerful magnets. If you're familiar with JSP and EJB, you are naturally tempted to choose those technologies early on. That's like adding quite a few powerful magnets again. Or maybe it's like adding a magnetic shield: it really depends on context.
Sometimes, technology makes the field simpler: the right infrastructure should simplify the field, that is, it should act more like a shield than like a magnet. In this sense, infrastructure should be chosen when the dominant forces are known, unlike what happens in many projects, where infrastructure (usually a superstructure in disguise) is chosen too early, thereby making the overall field even more complex.
We also shape the field, so to speak, by choosing what to ignore and what to postpone in any given release. Anything we ignore, like anything we postpone, won't be allowed to shape the field right now.
This is fine, as long as the corresponding magnets will be placed somehow distant from the others (good modularity), possibly with some kind of magnetic shielding in between (stable interfaces). It's also fine if we can ignore it forever. Any attempt to temporarily ignore a strictly interacting force will wreak havoc later on, as our form will no longer match the resulting force field. Refactoring can accommodate minor misfits with the ideal form, but won't help much when the force field changes radically (see also my notes on refactoring here).
Here lies one of the architect's fundamental abilities: the intuitive understanding that something can be beneficially postponed, while something else must be dealt with immediately, because its influence on the force field is so strong that doing otherwise will shift us toward the wrong kind of form.
It is important to understand the role of choice in exploiting instability. Too often, software developers tend to see requirements as "fixed". They don't like to negotiate: it's much easier to fight the compiler than the marketing guys.
A good architect, however, can't miss the opportunity to simplify the field by moving some magnets around. That requires the ability to see the overall picture and the fine details at the same time. Here is Alexander again (page 18): "this ability to deal with several layers of form-context boundaries in concert is an important part of what we often refer to as the designer's sense of organization. The internal coherence of an ensemble depends on a whole net of such adaptations".
That ain't an easy feat. It requires an understanding of the business, the users, and the technology. And even more important, it requires a willingness to act on that knowledge. The power of choice extends to the infrastructure: sometimes, by willingly postponing a technological choice until the force fields takes shape, we can make a better, more "natural" choice.
This can be hard for some developers: they want certainty, and they want it now. In my experience, that goes in pair with the willingness to adopt a sub-optimal, but repetitive and context free solution for a wide class of problems, instead of adopting several optimal, but reasoned and context-dependent solution for smaller classes of problems.
Unfortunately, choosing the "wrong" technology is very much like choosing the wrong shape or orientation for a building. To quote Alexander once again (page 29): "Instead of orienting the house carefully for sun and wind, the builder conceives its organization without concern for orientation, and light, heat, and ventilation are taken care of by fans, lamps, and other kinds of peripheral devices. Bedrooms are not separated from living rooms in plan, but are placed next to one another and the walls between them stuffed with acoustic insulation".
I think we can easily see a parallel with software here: a misfit technology is chosen early on. As a consequence, you find yourself adding more and more technology (fans, lamps, insulation) to satisfy the end-user needs. "Modern" web applications seem to have taken this path: faced with a difficult field, they're layering one technology on top the other, desperately trying to overcome the problems of the previous layer.
Next time, in no particular order: agility, unstable requirements, early coding, TDD, "seeing" the field, internal and external representations, is UML any useful, order within chaos (dominant forces), constructive force field and systematic techniques, and whatever else will come to my mind :-).
The notion of force field might be unfamiliar to some, so I'll borrow a great example from Alexander himself. Consider your first "requirement" (for a system yet to be built) as a permanent magnet of some size and shape. If you place a flat glass over that magnet, and drop some iron filings on it, the iron will naturally dispose along the magnetic field lines. That gives us an image of [a section of] the force field. Now add another magnet: the shape of the field will change, as the magnets are interacting, thereby shaping a more complex force field.
We can change the [shape of the] field in many ways: moving magnets around, changing their shape, their magnetization, or even adding some shields around magnets.
The great thing about the magnetic field is that we can somehow observe its shape. Indeed, if our goal was to create a form that can be put into effortless contact with the field, we'll just have to replicate the same form that the magnetic field is giving to the iron filings. As Alexander says (NoTSoF, page 21), "once we have a diagram of forces [...] this will in essence also describe the form as a complementary diagram of forces".
In the real world, and even more so in the software world, we are never so lucky: the force field is invisible and tends also to be highly unstable.
Usually, the force field of a software project starts with Requirements. Requirements are often categorized in some way, like "functional" and "nonfunctional", or "user requirements" and "system requirements. However, requirements of any kind are just like magnets: they contribute to shape the overall field.
Requirements are just one kind of force, that is, they are not alone in shaping the field. Many technological choices we make, sometimes very (or too) early, are also shaping the force field.
Consider a simple business application. Once you decide that you'll build a web application, you have added quite a few powerful magnets. If you're familiar with JSP and EJB, you are naturally tempted to choose those technologies early on. That's like adding quite a few powerful magnets again. Or maybe it's like adding a magnetic shield: it really depends on context.
Sometimes, technology makes the field simpler: the right infrastructure should simplify the field, that is, it should act more like a shield than like a magnet. In this sense, infrastructure should be chosen when the dominant forces are known, unlike what happens in many projects, where infrastructure (usually a superstructure in disguise) is chosen too early, thereby making the overall field even more complex.
We also shape the field, so to speak, by choosing what to ignore and what to postpone in any given release. Anything we ignore, like anything we postpone, won't be allowed to shape the field right now.
This is fine, as long as the corresponding magnets will be placed somehow distant from the others (good modularity), possibly with some kind of magnetic shielding in between (stable interfaces). It's also fine if we can ignore it forever. Any attempt to temporarily ignore a strictly interacting force will wreak havoc later on, as our form will no longer match the resulting force field. Refactoring can accommodate minor misfits with the ideal form, but won't help much when the force field changes radically (see also my notes on refactoring here).
Here lies one of the architect's fundamental abilities: the intuitive understanding that something can be beneficially postponed, while something else must be dealt with immediately, because its influence on the force field is so strong that doing otherwise will shift us toward the wrong kind of form.
It is important to understand the role of choice in exploiting instability. Too often, software developers tend to see requirements as "fixed". They don't like to negotiate: it's much easier to fight the compiler than the marketing guys.
A good architect, however, can't miss the opportunity to simplify the field by moving some magnets around. That requires the ability to see the overall picture and the fine details at the same time. Here is Alexander again (page 18): "this ability to deal with several layers of form-context boundaries in concert is an important part of what we often refer to as the designer's sense of organization. The internal coherence of an ensemble depends on a whole net of such adaptations".
That ain't an easy feat. It requires an understanding of the business, the users, and the technology. And even more important, it requires a willingness to act on that knowledge. The power of choice extends to the infrastructure: sometimes, by willingly postponing a technological choice until the force fields takes shape, we can make a better, more "natural" choice.
This can be hard for some developers: they want certainty, and they want it now. In my experience, that goes in pair with the willingness to adopt a sub-optimal, but repetitive and context free solution for a wide class of problems, instead of adopting several optimal, but reasoned and context-dependent solution for smaller classes of problems.
Unfortunately, choosing the "wrong" technology is very much like choosing the wrong shape or orientation for a building. To quote Alexander once again (page 29): "Instead of orienting the house carefully for sun and wind, the builder conceives its organization without concern for orientation, and light, heat, and ventilation are taken care of by fans, lamps, and other kinds of peripheral devices. Bedrooms are not separated from living rooms in plan, but are placed next to one another and the walls between them stuffed with acoustic insulation".
I think we can easily see a parallel with software here: a misfit technology is chosen early on. As a consequence, you find yourself adding more and more technology (fans, lamps, insulation) to satisfy the end-user needs. "Modern" web applications seem to have taken this path: faced with a difficult field, they're layering one technology on top the other, desperately trying to overcome the problems of the previous layer.
Next time, in no particular order: agility, unstable requirements, early coding, TDD, "seeing" the field, internal and external representations, is UML any useful, order within chaos (dominant forces), constructive force field and systematic techniques, and whatever else will come to my mind :-).
Friday, April 25, 2008
Can AOP inform OOP (toward SOA, too? :-) [part 2]
Aspect-oriented programming is still largely code-centric. This is not surprising, as OOP went through the same process: early emphasis was on coding, and it took quite a few years before OOD was ready for prime time. The truth about OOA is that it never really got its share (guess use cases just killed it).
This is not to say that nobody is thinking about the so-called early aspects. A notable work is the Theme Approach (there is also a good book about Theme). Please stay away from the depressing idea that use cases are aspects; as I said a long time ago, it's just too lame.
My personal view on early aspects is quite simple: right now, I mostly look for cross-cutting business rules as candidate aspects. I guess it's quite obvious that the whole "friend gift" concept is a business rule cutting through User and Subscription, and therefore a candidate aspect. Although I'm not saying that all early aspects are cross-cutting business rules (or vice-versa), so far this simple guideline has served me well in a number of cases.
It is interesting to see how early aspects tend to be cross-cutting (that is, they hook into more than one class) but not pervasive. An example of pervasive concern is the ubiquitous logging. Early aspects tend to cut through a few selected classes, and tend to be non-reusable (while a logging aspect can be made highly reusable).
This seems at odd with the idea that "AOP is not for singleton", but I've already expressed my doubt on the validity of this suggestion a long time ago. It seems to me that AOP is still in its infancy when it comes to good principles.
Which brings me to obliviousness. Obliviousness is an interesting concept, but just as it happened with inheritance in the early OOP days, people tend to get carried over.
Remember when white-box inheritance was applied without understanding (for instance) the fragile base class problem?
People may view inheritance as a way to "patch" a base class and change its behaviour in unexpected ways. But truth is, a base class must be designed to be extended, and extension can take place only through well-defined extensions hot-points. It is not a rare occurrence to refactor a base class to make extension safer.
Aspects are not really different. People may view aspects as a way to "patch" existing code and change its behaviour in unexpected ways. But truth is, when you move outside the safe realm of spectators (see my post above for more), your code needs to be designed for interception.
Consider, for instance, the initial idea of patching the User class through aspects, adding a data member, and adding a corresponding data into the database. Can your persistence logic be patched through an aspect? Well, it depends!
Existing AOP languages can't advise any given line: there is a fixed grammar for pointcuts, like method call, data member access, and so on. So if your persistence code was (trivially)
Is this really different from exposing a CreateSubscription event? Yeah, well, it's more code to write. But in many data-oriented applications, a well-administered dose of events in the CRUD methods can take you a long way toward a more flexible architecture.
A closing remark on the SOA part. SOA is still much of a buzzword, and many good [design] ideas are still in the decontextualized stage, where people are expected to blindly follow some rule without understanding the impact of what they're doing.
In my view, a crucial step toward SOA is modularity. Modularity has to take place at all levels, even (this will sound like an heresy to some) at the database level. Ideally (this is not a constraint to be forced, but a force to be considered) every service will own its own tables. No more huge SQL statements traversing every tidbit in the database.
Therefore, if you consider the "friend gift" as a separate service, it is only natural to avoid tangling the User class, the Subscription class, and the User table with information that just doesn't belong there. In a nutshell, separating a cross-cutting business rule into an aspect-like class will bring you to a more modular architecture, and modularity is one of the keys to true SOA.
This is not to say that nobody is thinking about the so-called early aspects. A notable work is the Theme Approach (there is also a good book about Theme). Please stay away from the depressing idea that use cases are aspects; as I said a long time ago, it's just too lame.
My personal view on early aspects is quite simple: right now, I mostly look for cross-cutting business rules as candidate aspects. I guess it's quite obvious that the whole "friend gift" concept is a business rule cutting through User and Subscription, and therefore a candidate aspect. Although I'm not saying that all early aspects are cross-cutting business rules (or vice-versa), so far this simple guideline has served me well in a number of cases.
It is interesting to see how early aspects tend to be cross-cutting (that is, they hook into more than one class) but not pervasive. An example of pervasive concern is the ubiquitous logging. Early aspects tend to cut through a few selected classes, and tend to be non-reusable (while a logging aspect can be made highly reusable).
This seems at odd with the idea that "AOP is not for singleton", but I've already expressed my doubt on the validity of this suggestion a long time ago. It seems to me that AOP is still in its infancy when it comes to good principles.
Which brings me to obliviousness. Obliviousness is an interesting concept, but just as it happened with inheritance in the early OOP days, people tend to get carried over.
Remember when white-box inheritance was applied without understanding (for instance) the fragile base class problem?
People may view inheritance as a way to "patch" a base class and change its behaviour in unexpected ways. But truth is, a base class must be designed to be extended, and extension can take place only through well-defined extensions hot-points. It is not a rare occurrence to refactor a base class to make extension safer.
Aspects are not really different. People may view aspects as a way to "patch" existing code and change its behaviour in unexpected ways. But truth is, when you move outside the safe realm of spectators (see my post above for more), your code needs to be designed for interception.
Consider, for instance, the initial idea of patching the User class through aspects, adding a data member, and adding a corresponding data into the database. Can your persistence logic be patched through an aspect? Well, it depends!
Existing AOP languages can't advise any given line: there is a fixed grammar for pointcuts, like method call, data member access, and so on. So if your persistence code was (trivially)
class Userthere would be no way to participate to the transaction from an aspect. You would have to refactor your code, e.g. by moving the SQL part in a separate method, taking the transaction as a parameter. Can we still call this obliviousness? That's highly debatable! I may not know the details of the advice, but I damn sure know I'm being advised, as I refactored my code to be pointcut-friendly.
{
void Save()
{
// open a transaction
// do your SQL stuff
// close the transaction
}
}
Is this really different from exposing a CreateSubscription event? Yeah, well, it's more code to write. But in many data-oriented applications, a well-administered dose of events in the CRUD methods can take you a long way toward a more flexible architecture.
A closing remark on the SOA part. SOA is still much of a buzzword, and many good [design] ideas are still in the decontextualized stage, where people are expected to blindly follow some rule without understanding the impact of what they're doing.
In my view, a crucial step toward SOA is modularity. Modularity has to take place at all levels, even (this will sound like an heresy to some) at the database level. Ideally (this is not a constraint to be forced, but a force to be considered) every service will own its own tables. No more huge SQL statements traversing every tidbit in the database.
Therefore, if you consider the "friend gift" as a separate service, it is only natural to avoid tangling the User class, the Subscription class, and the User table with information that just doesn't belong there. In a nutshell, separating a cross-cutting business rule into an aspect-like class will bring you to a more modular architecture, and modularity is one of the keys to true SOA.
Thursday, April 24, 2008
Can AOP inform OOP (toward SOA, too? :-) [part 1]
Note: I began tinkering with this idea several months ago, inspired by some design work I was doing on a real-world project. Initially, I thought I could pimp up this stuff into a full-fledged article. Months came by and I didn't, so (in the spirit of my old concept of Blogging as Destructuring) I thought I could just as well say something here instead.
Consider a web site offering some kind of service to users. Users have to register (yeah :-), and they can then buy a subscription to several services. A simple class diagram can model this easily:
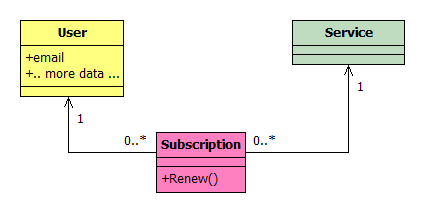
In most cases, the underlying database schema wouldn't be much different.
In a real case, there might be different kind of services, each requiring a derived class, but we can ignore this issue right now. Also, there might be several kind of subscription (time-based, pay-per-use, and so on), but again, let's ignore that issue right now, and just concentrate on time-base subscriptions.
A subscription can be renewed at any time. In the object model, this would translate into a Renew method in class Subscription. Renew could take a parameter, like the extension of the renewal. Most likely, it would add a new record to the Subscription table (to keep track of the whole subscription history for that user), and possibly create a new Subscription object. So far, so good.
Now the marketing guys come up with a nice idea: whenever you register, you can provide the email address of a friend who has already registered. If you do, everytime you renew a subscription your friend will get some kind of gift, like a free extension or whatever. This may generate a few more leads, meaning a little more business.
From a purely OO mindset, this may lead us to perform a little maintenance on the existing model. We can add a relationship from User to User to model the "friend" relationship, or we could just add a field like friendEmail (possibly left empty). At the database level, adding a field is probably easier.
We can also modify the Renew method to check for the presence of a friend in the subscribing user, and if so, invoke some Gift logic. I won't draw a modified diagram for this scenario: I guess it's just too obvious.
Now, this approach obviously works. However, you may recognize that the whole "friend gift" concept is a cross-cutting concern: it cuts through User (requiring new data) and through Subscription (requiring new logic). More on detecting cross-cutting concerns during analysis and design (and on the difference between cross-cutting and pervasive concerns) next time.
In the AOP world, we could approach the problem differently. We could define a FriendGift aspect. The aspect may add a new data member to the User class (the friendEmail), and intercept the persistence logic to save / load that data from the database. The aspect may also intercept Renew and perform the Gift logic if required.
Actually the aspect doesn't have to modify User (class and table); indeed, it would be better not to, as the persistence logic might not be easy to intercept (more on this next time). The aspect could just use a different database table to store the friend email.
Using an UML-like notation, we could model this approach as:
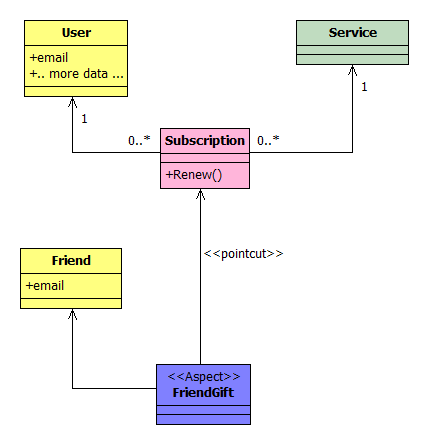
Interestingly, the database is probably different from the previous scenario: Friend would map to its own table.
What if we are not using an AOP-enabled language? For instance, we might be using plain old C#. Can we still borrow some ideas from the above? I believe so. In the same sense as OO thinking can inform traditional structured programming, AOP thinking can inform traditional object oriented programming.
If we don't have pointcuts, join points and aspects, we may still have events (in C#/.NET, or callback in other languages, and so on). Sure, we have to forego obliviousness (which might not be so bad: more on this next time). But we can come up with a more modular and decoupled design by reasoning along the AOP lines:

No rocket science here :-). Just a different form, same function. Different database, a more general Subscription class, unaffected by a business rule which may change at any time. Also the User class and table are left unaffected.
More on this, and a few comments on the SOA part, in just a few days (I hope :-).
Consider a web site offering some kind of service to users. Users have to register (yeah :-), and they can then buy a subscription to several services. A simple class diagram can model this easily:
In most cases, the underlying database schema wouldn't be much different.
In a real case, there might be different kind of services, each requiring a derived class, but we can ignore this issue right now. Also, there might be several kind of subscription (time-based, pay-per-use, and so on), but again, let's ignore that issue right now, and just concentrate on time-base subscriptions.
A subscription can be renewed at any time. In the object model, this would translate into a Renew method in class Subscription. Renew could take a parameter, like the extension of the renewal. Most likely, it would add a new record to the Subscription table (to keep track of the whole subscription history for that user), and possibly create a new Subscription object. So far, so good.
Now the marketing guys come up with a nice idea: whenever you register, you can provide the email address of a friend who has already registered. If you do, everytime you renew a subscription your friend will get some kind of gift, like a free extension or whatever. This may generate a few more leads, meaning a little more business.
From a purely OO mindset, this may lead us to perform a little maintenance on the existing model. We can add a relationship from User to User to model the "friend" relationship, or we could just add a field like friendEmail (possibly left empty). At the database level, adding a field is probably easier.
We can also modify the Renew method to check for the presence of a friend in the subscribing user, and if so, invoke some Gift logic. I won't draw a modified diagram for this scenario: I guess it's just too obvious.
Now, this approach obviously works. However, you may recognize that the whole "friend gift" concept is a cross-cutting concern: it cuts through User (requiring new data) and through Subscription (requiring new logic). More on detecting cross-cutting concerns during analysis and design (and on the difference between cross-cutting and pervasive concerns) next time.
In the AOP world, we could approach the problem differently. We could define a FriendGift aspect. The aspect may add a new data member to the User class (the friendEmail), and intercept the persistence logic to save / load that data from the database. The aspect may also intercept Renew and perform the Gift logic if required.
Actually the aspect doesn't have to modify User (class and table); indeed, it would be better not to, as the persistence logic might not be easy to intercept (more on this next time). The aspect could just use a different database table to store the friend email.
Using an UML-like notation, we could model this approach as:
Interestingly, the database is probably different from the previous scenario: Friend would map to its own table.
What if we are not using an AOP-enabled language? For instance, we might be using plain old C#. Can we still borrow some ideas from the above? I believe so. In the same sense as OO thinking can inform traditional structured programming, AOP thinking can inform traditional object oriented programming.
If we don't have pointcuts, join points and aspects, we may still have events (in C#/.NET, or callback in other languages, and so on). Sure, we have to forego obliviousness (which might not be so bad: more on this next time). But we can come up with a more modular and decoupled design by reasoning along the AOP lines:
No rocket science here :-). Just a different form, same function. Different database, a more general Subscription class, unaffected by a business rule which may change at any time. Also the User class and table are left unaffected.
More on this, and a few comments on the SOA part, in just a few days (I hope :-).
Wednesday, March 19, 2008
(Simple) Metrics
I've been using metrics for a long time (certainly more than 10 years now). I've been using metrics to control project quality (including my own stuff, of course), to define acceptance criteria for outsourced code, to understand the way people work, to "smell" large projects before attempting a refactoring activity, to help making an informed refactor / rewrite decision, to pinpoint functions or classes in need of a careful review, to estimate residual bugs, an so on.
Of course, I use different metrics for different purposes. I also combine metrics to get the right picture. In fact, you can now find several tools to calculate (e.g.) code metrics. You can also find many papers discussing (often with contradictory results) the correlation between any given metric and (e.g.) bug density. In most cases, those papers are misguided, as they look for correlation between a single metric and the target (like bug density). Reality is not that simple; it can be simplified, but not to that point.
Consider good old cyclomatic complexity. You can use it as-is, and it can be useful to calculate the minimum reasonable number of test cases you need for a single function. It's also known that functions with higher cyclomatic complexity tend to have more bugs. But it's also well known that (on average) there is a strong, positive correlation between cyclomatic complexity (CC) and lines of code (LOC). That's really natural: long functions tend to have a complex control flow. Many people have therefore discounted CC, as you can just look at the highly correlated (and easier to calculate) LOC. Simple reasoning, except it's wrong :-).
The problem with that, again, is trying to use just one number to understand something that's too complex to be represented by a single number. A better way is to get both CC and LOC for any function (or method) and then use quadrants.
Here is a real-world example, albeit from a very small program: a smart client invoking a few web services and dealing with some large XML files on the client side. It has been written in C# using Visual Studio, therefore some methods are generated by the IDE. Also, the XML parser is generated from the corresponding XSD. Since I'm concerned with code which is under the programmer's control, I've excluded all the generated files, resulting in about 20 classes. For each method, I gathered the LOC and CC count (more on "how" later). I used Excel to get the following picture:

As you can see, every method is just a dot in the chart, and the chart has been split in 4 quadrants. I'll discuss the thresholds later, as it's more important to understand the meaning of each quadrant first.
The lower-left quadrant is home for low-LOC, low-CC methods. These are the best methods around: short and simple. Most code ought to be there (as it is in this case).
Moving clockwise, the next you get (top-left) is for high LOC, low CC methods. Although most coding standards tend to somehow restrict the maximum length of any given method, it's pretty obvious that a long method with a small CC is not that bad. It's "linear" code, likely doing some initialization / configuration. No big deal.
The next quadrant (top-right) is for high LOC, high CC methods. Although this might seem the worst quadrant, it is not. High LOC means an opportunity for simple refactoring (extract method, create class, stuff like that). The code would benefit from changes, but those changes may require relatively little effort (especially if you can use refactoring tools).
The lower-right quadrant is the worst: short functions with high CC (there are none in this case). These are the puzzling functions which can pack a lot of alternative paths into just a few lines. In most cases, it's better to leave them alone (if working) or rewrite them from scratch (if broken). When outsourcing, I usually ask that no code falls in this quadrant.
For the project at hand, 3 classes were in quadrant 3, so candidate for refactoring. I took a look, and guess what, it was pretty obvious that those methods where dealing with business concerns inside the GUI. There were clearly 3 domain classes crying to be born (1 shared by the three methods, 1 shared by 2, one used by the remaining). Doing so brought to better code, with little effort. This is a rather ordinary experience: quadrants pinpoint problematic code, then it's up to the programmer/designer to find the best way to fix it (or decide to leave it as it is).
A few words on the thresholds: 10 is a rather generous, but somewhat commonly accepted threshold for CC. The threshold for LOC depends heavily on the overall project quality. I've been accepting a threshold of 100 in quality-challenged projects. As the quality improves (through refactoring / rewriting) we usually lower the threshold. Being a new development, I adopted 20 LOC as a rather reasonable threshold.
As I said, I use several different metrics. Some can be used in isolation (like code clones), but in most cases I combine them (for instance, code clones vs. code stability gives a better picture of the problem). Coupling and cohesion should also be considered as pairs, never as single numbers, and so on.
Quadrants are not necessarily the only tool: sometimes I also look at the distribution function of a single metric. This is way superior to what too many people tend to do (like looking at the "average CC", which is meaningless). As usual, a tool is useless if we can't use it effectively.
Speaking of tools, the project above was in C#, so I used Source Monitor, a good free tool working directly on C# sources. Many .NET tools work on the MSIL instead, and while that may seem like a good idea, in practice it doesn't help much when you want a meaningful LOC count :-).
Source Monitor can export in CSV and XML. Unfortunately, the CSV didn't contain the detailed data I wanted, so I had to use the XML. I wrote a short XSLT file to extract the data I needed in CSV format (I suggest you use the "save as" feature, as unwanted spacing / carriage returns added by browsers may cripple the result). Use it freely: I didn't put a license statement inside, but all [my] source code in this blog can be considered under the BSD license unless otherwise stated.
Of course, I use different metrics for different purposes. I also combine metrics to get the right picture. In fact, you can now find several tools to calculate (e.g.) code metrics. You can also find many papers discussing (often with contradictory results) the correlation between any given metric and (e.g.) bug density. In most cases, those papers are misguided, as they look for correlation between a single metric and the target (like bug density). Reality is not that simple; it can be simplified, but not to that point.
Consider good old cyclomatic complexity. You can use it as-is, and it can be useful to calculate the minimum reasonable number of test cases you need for a single function. It's also known that functions with higher cyclomatic complexity tend to have more bugs. But it's also well known that (on average) there is a strong, positive correlation between cyclomatic complexity (CC) and lines of code (LOC). That's really natural: long functions tend to have a complex control flow. Many people have therefore discounted CC, as you can just look at the highly correlated (and easier to calculate) LOC. Simple reasoning, except it's wrong :-).
The problem with that, again, is trying to use just one number to understand something that's too complex to be represented by a single number. A better way is to get both CC and LOC for any function (or method) and then use quadrants.
Here is a real-world example, albeit from a very small program: a smart client invoking a few web services and dealing with some large XML files on the client side. It has been written in C# using Visual Studio, therefore some methods are generated by the IDE. Also, the XML parser is generated from the corresponding XSD. Since I'm concerned with code which is under the programmer's control, I've excluded all the generated files, resulting in about 20 classes. For each method, I gathered the LOC and CC count (more on "how" later). I used Excel to get the following picture:
As you can see, every method is just a dot in the chart, and the chart has been split in 4 quadrants. I'll discuss the thresholds later, as it's more important to understand the meaning of each quadrant first.
The lower-left quadrant is home for low-LOC, low-CC methods. These are the best methods around: short and simple. Most code ought to be there (as it is in this case).
Moving clockwise, the next you get (top-left) is for high LOC, low CC methods. Although most coding standards tend to somehow restrict the maximum length of any given method, it's pretty obvious that a long method with a small CC is not that bad. It's "linear" code, likely doing some initialization / configuration. No big deal.
The next quadrant (top-right) is for high LOC, high CC methods. Although this might seem the worst quadrant, it is not. High LOC means an opportunity for simple refactoring (extract method, create class, stuff like that). The code would benefit from changes, but those changes may require relatively little effort (especially if you can use refactoring tools).
The lower-right quadrant is the worst: short functions with high CC (there are none in this case). These are the puzzling functions which can pack a lot of alternative paths into just a few lines. In most cases, it's better to leave them alone (if working) or rewrite them from scratch (if broken). When outsourcing, I usually ask that no code falls in this quadrant.
For the project at hand, 3 classes were in quadrant 3, so candidate for refactoring. I took a look, and guess what, it was pretty obvious that those methods where dealing with business concerns inside the GUI. There were clearly 3 domain classes crying to be born (1 shared by the three methods, 1 shared by 2, one used by the remaining). Doing so brought to better code, with little effort. This is a rather ordinary experience: quadrants pinpoint problematic code, then it's up to the programmer/designer to find the best way to fix it (or decide to leave it as it is).
A few words on the thresholds: 10 is a rather generous, but somewhat commonly accepted threshold for CC. The threshold for LOC depends heavily on the overall project quality. I've been accepting a threshold of 100 in quality-challenged projects. As the quality improves (through refactoring / rewriting) we usually lower the threshold. Being a new development, I adopted 20 LOC as a rather reasonable threshold.
As I said, I use several different metrics. Some can be used in isolation (like code clones), but in most cases I combine them (for instance, code clones vs. code stability gives a better picture of the problem). Coupling and cohesion should also be considered as pairs, never as single numbers, and so on.
Quadrants are not necessarily the only tool: sometimes I also look at the distribution function of a single metric. This is way superior to what too many people tend to do (like looking at the "average CC", which is meaningless). As usual, a tool is useless if we can't use it effectively.
Speaking of tools, the project above was in C#, so I used Source Monitor, a good free tool working directly on C# sources. Many .NET tools work on the MSIL instead, and while that may seem like a good idea, in practice it doesn't help much when you want a meaningful LOC count :-).
Source Monitor can export in CSV and XML. Unfortunately, the CSV didn't contain the detailed data I wanted, so I had to use the XML. I wrote a short XSLT file to extract the data I needed in CSV format (I suggest you use the "save as" feature, as unwanted spacing / carriage returns added by browsers may cripple the result). Use it freely: I didn't put a license statement inside, but all [my] source code in this blog can be considered under the BSD license unless otherwise stated.
Subscribe to:
Posts (Atom)